#008: Improving deployment visibility with small, targeted tools
One of the first things I do when I join a new team is dig into their CI/CD process. This usually involves asking a few simple questions:
How is infrastructure provisioned?
How is software deployed?
How are deployment updates communicated to the team?
Are differences between environments highlighted?
As a Tech Lead, I try to make sure that developers on my team have a clear sense of the above. Over the years, I’ve found that teams move faster when everyone understands how infrastructure and application changes flow from local machines through development environments and into production. Not only that, knowing exactly what infrastructure is being provisioned or what changes are being shipped with a deployment leads to fewer surprises, and more importantly, fewer incidents.
The team I recently joined at my place of work runs apps on Kubernetes, with Argo CD handling deployments from a GitOps repo. Infrastructure lives in a separate Terraform/OpenTofu repo, managed with Terragrunt for multi-environment/multi-region deployments.
The Challenges
This setup creates some visibility challenges. With infrastructure changes decoupled from app code, developers have to manually ensure that the correct infrastructure is running in an environment before code can be deployed to it. If an app is not coded defensively, an oversight like this can lead to failures upon deployment. Furthermore, there are no guarantees that infrastructure in two regions belonging to the same environment will always be in sync, which can lead to issues.
The GitOps model creates a layer of indirection when it comes to tracking code
changes between environments. Want to see what changes have piled up on dev
since the last deployment to prod? Fetch the app versions for both environments from
the GitOps repo, then check the commit log between them on GitHub, or via git
locally.
The Setup: Infrastructure
The infrastructure repository is organized in a three-tier hierarchy: environment (dev, prod), region (Virginia, Oregon, Frankfurt), and stack (core infrastructure, Kubernetes management, and apps). The repository contains several reusable modules (VPC, EKS, RDS, Neptune, MSK, etc.), which are referenced in the stacks.
.
├── environments
│ ├── dev
│ │ ├── frankfurt
│ │ │ └── infra
│ │ └── virginia
│ │ ├── apps <--- this holds the apps, each tagged to a version
│ │ ├── cicd
│ │ ├── infra
│ │ └── k8s-mgmt
│ └── prod
│ ├── frankfurt
│ │ ├── apps
│ │ ├── infra
│ │ └── k8s-mgmt
│ └── virginia
│ ├── apps
│ ├── infra
│ └── k8s-mgmt
├── modules
│ ├── applications
│ │ ├── app-a <--- this defines the infra for an app
│ │ ├── app-b
│ │ └── app-c
│ ├── other-module-1
│ ├── other-module-2
│ ├── other-module-3
│ └── and_so_on
└── tflens.ymlEach Terraform stack is composed of several modules, each pinned to a specific version:
# environments/prod/virginia/apps/main.tf
module "app_a" {
source = "git@github.com:owner/repo//modules/applications/app-a?ref=applications-app-a-v1.0.22"
environment = var.environment
other = "fields"
go = "here"
}
module "app_b" {
source = "git@github.com:owner/repo//modules/applications/app-b?ref=applications-app-b-v2.0.0"
environment = var.environment
this = "has"
fields = "too"
}When a developer needs to add new infrastructure resources or modify them, they:
- update the module code
- tag it with a new version
- reference that tag in the relevant Terraform stack
This provides deployment flexibility, e.g., you can deploy infrastructure
changes in the dev environment before promoting them to prod.
The Setup: GitOps
The GitOps repository contains Helm charts for each application, organized by environment. Each application’s individual CI/CD updates the Helm values in the application’s directory. Argo CD watches this repository and deploys changes when it detects updates to it.
Here’s how the repository is structured:
.
├── dev
│ ├── app-1
│ │ ├── Chart.yaml
│ │ ├── templates
│ │ │ ├── _helpers.tpl
│ │ │ ├── deployment.yaml
│ │ │ ├── ingress.yaml
│ │ │ ├── service.yaml
│ │ │ └── serviceaccount.yaml
│ │ └── values.yaml <--- this holds the application version
│ └── app-2
│ ├── Chart.yaml
│ ├── templates
│ │ ├── _helpers.tpl
│ │ ├── serviceaccount.yaml
│ │ └── workflow.yaml
│ └── values.yaml
└── prod
├── app-1
│ ├── Chart.yaml
│ ├── templates
│ │ ├── _helpers.tpl
│ │ ├── serviceaccount.yaml
│ │ └── workflow.yaml
│ └── values.yaml
└── app-2
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── service.yaml
│ └── serviceaccount.yaml
└── values.yamlThe Solution
There are many areas for improvement in this model, but I wanted to tackle the issue of visibility first. The idea is to equip developers with the tools to access the information they need quickly. To achieve this, I decided to set up a centralized dashboard where developers can get answers to the following questions:
- Are there differences in infrastructure between different environments (and/or regions)?
- Are the application versions between different environments in sync? If not, what source code changes exist between them?
To do this, I wrote two small tools: tflens and envee.
tflens
tflens is a simple command-line tool that parses Terraform HCL files and generates a single table showing each module version across all environment/region combinations. It relies on a configuration file like the following.
compareModules:
comparisons:
- name: apps
attributeKey: source
sources:
- path: environments/dev/virginia/apps/main.tf
label: dev
- path: environments/prod/virginia/apps/main.tf
label: prod-us
- path: environments/prod/frankfurt/apps/main.tf
valueRegex: "v?(\\d+\\.\\d+\\.\\d+)"
label: prod-eu
valueRegex: "v?(\\d+\\.\\d+\\.\\d+)"In this configuration, tflens reads the module attribute referenced by
attributeKey (here, source) and applies valueRegex to extract a semantic
version. You can set a global valueRegex and override it per source when
formats differ.
tflens compare-modules apps module dev prod-us prod-eu in-sync
module_a 1.0.24 1.0.24 1.0.24 ✓
module_b 0.2.0 0.2.0 - ✗
module_c 1.1.1 1.1.1 1.0.0 ✗The “in-sync” column immediately surfaces drift: module_c is at 1.0.0 in
Frankfurt prod but 1.1.1 in Virginia prod. That’s a production issue
waiting to happen.
Since the tool needs to parse HCL source code, Go was the natural choice for implementation — the official HCL parser is written in Go. I added HTML output as well for sharing reports with the team.

envee
The second visibility gap was application versions:
Which version of each app is running where?
How far behind is prod from dev?
What commits are we about to deploy?
envee answers these questions by showing all app versions in one place, with
commit logs between them. It requires a TOML file that holds information for the
various apps and the versions they’re running. I generate this using a simple
Python script that traverses the GitOps repository. In our setup, the “version”
corresponds to the container image tag stored in each app’s values.yaml.
envs = ["dev", "prod"]
github_org = "org"
git_tag_transform = "v{{version}}"
[[versions]]
app = "app-a"
env = "dev"
version = "0.1.2"
[[versions]]
app = "app-a"
env = "prod"
version = "0.1.0"
[[versions]]
app = "app-b"
env = "dev"
version = "1.2.0"
[[versions]]
app = "app-b"
env = "prod"
version = "1.2.0"Why the Python intermediary instead of parsing Helm YAML files directly?
Separation of concerns and simplicity. Having envee extract versions from our GitOps repository would tightly couple it to our workflows. Having written a tool before that pulls app versions from AWS ECS and displays them in this manner, I knew this time that I wanted envee to rely on a data file so it can work with other deployment models as well.
Here it is in action.
The HTML output shows the same information in a shareable format.
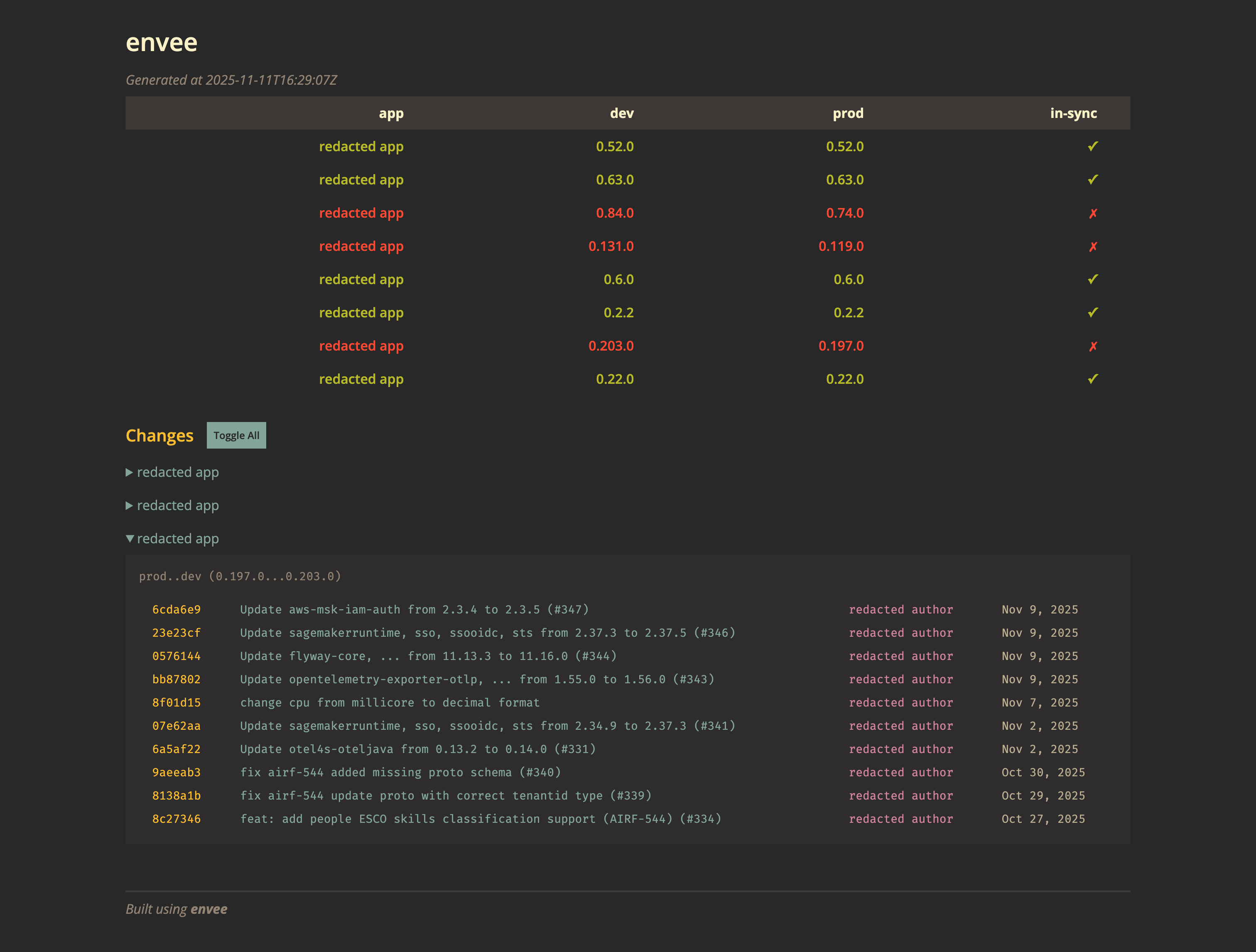
envee is written in Rust, and even though it’s a very simple tool, I enjoyed encoding the domain’s constraints in Rust’s type system, and testing every little corner of it with insta.
Go vs Rust: Building Similar Tools
Both tools solve the same class of problem — parse configuration files, process the data, generate reports. They process data as follows:
- parse runtime config into validated types
- fetch external data if needed; build a data structure representing the result
- derive a view from this data structure based on the output format chosen by the user
Even though the tools are quite simple, I felt more comfortable writing envee in Rust than I did writing tflens in Go. Rust’s type system and idioms seem to fit my mental models better and naturally guide me to better architectures. I wrote tflens first, but after writing envee, I ported some ideas back to tflens. Even though those ideas didn’t come to me naturally while writing Go, tflens got better after adopting them.
Bringing This Together
Both reports are deployed to the same GitHub Pages site. They’re regenerated on a schedule to keep the information up to date. My hope is that this will lower the friction for my teammates to fetch the state of infrastructure and app versions, and will lead to fewer deployment-related issues in the future.