#007: Adapting kplay to meet new needs
Kafka is the primary system for service-to-service messaging at my workplace. Most topics carry messages encoded with protobuf, a binary serialization format that’s efficient for storage and transmission but unreadable without the matching schema files. This makes inspecting message contents tricky. Tools like kafka-ui can decode messages when given the schemas, but I prefer command-line solutions.
To fill that gap, I built kplay last year. It lets users interactively pull messages from Kafka topics and view them in a TUI or web interface, with the option to save decoded messages locally. It quickly became a useful tool for me for investigating Kafka topics.
I recently joined a new team that works heavily with data, much of it coming from Kafka topics owned by another group. When we spotted some unusual behavior in one of these topics, we needed to dig deeper — specifically, by polling messages from certain offsets or timestamps. Unfortunately, kplay wasn’t up to the task: it only supported consuming as part of a consumer group, with no way to fetch by offset or timestamp. To make things harder, the topic was aggressively compacted, so older messages vanished within hours.
That limitation blocked proper inspection of the source topic. To solve it, I extended kplay with new capabilities, which shipped in version v3.0.0.
Polling from an offset/timestamp
The ability to pull from any offset or timestamp was straightforward to add. The TUI/web interface now lets you specify these parameters when consuming from a topic, making jumping around in a Kafka offset range easy.
Next came the ability to scan a range of offsets in a topic and save the decoded message values to the local filesystem. This batch processing mode proved helpful in analyzing historical data across large offset ranges.
Forwarding to S3
The last problem was aggressive compaction: my team needed an historical archive of the messages sent to the topic we consume from. For this, I added a feature to kplay that lets you forward decoded messages to an S3 bucket.
The requirements were:
- Allow running for multiple profiles at the same time
- Be fast, ie, process messages concurrently
- Allow running an optional HTTP server for health checks
- Be configurable (worker count, timeouts, polling intervals, etc.)
- Allow uploading processing reports (ie, a log of messages processed)
- Never lose data (messages or report entries)
Here’s how it works.
Architecture
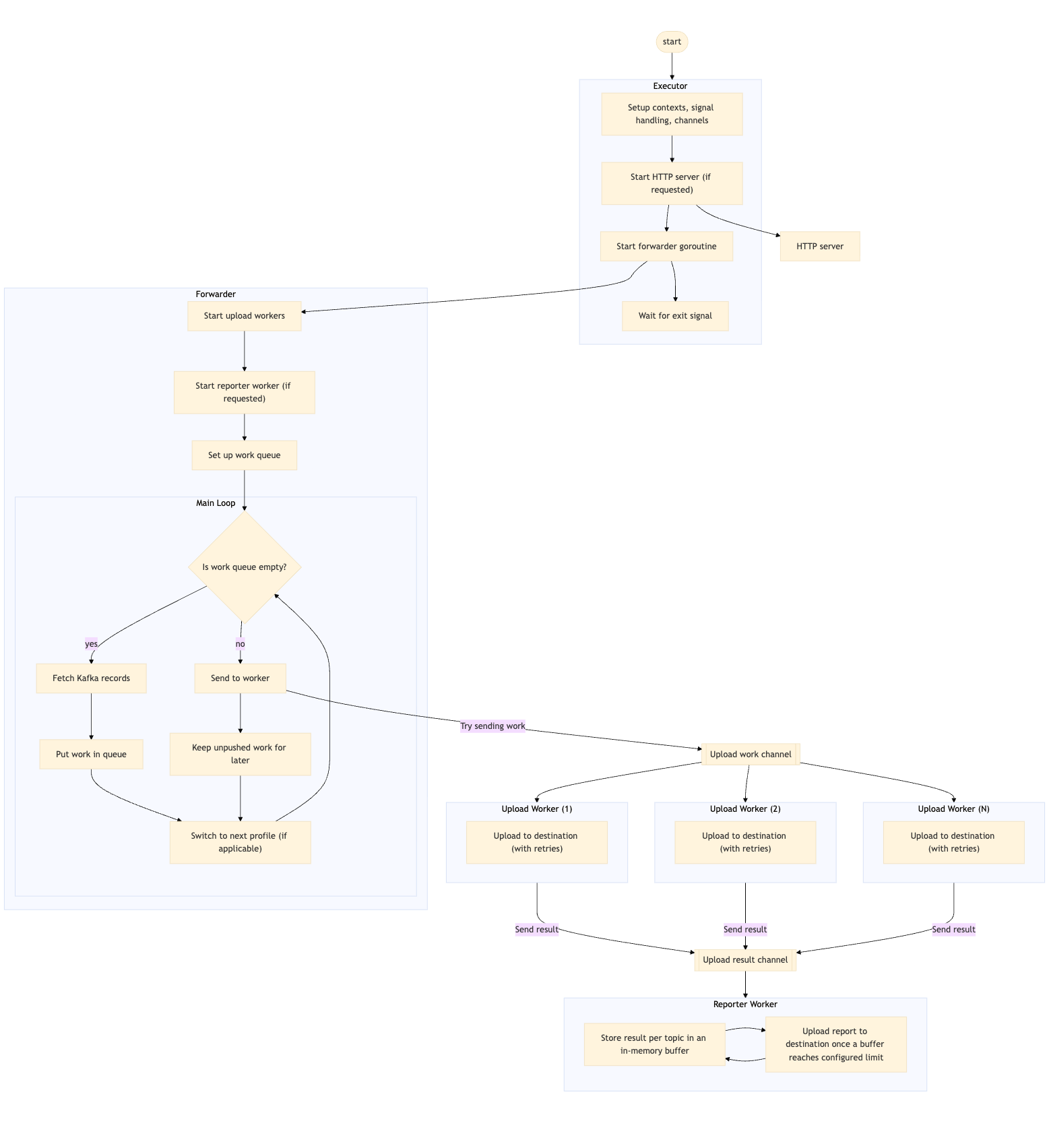
The forwarding architecture centers around a main executor that coordinates several concurrent components. If requested, the executor first starts an HTTP server for health checks, then launches the main forwarder goroutine.
The forwarder operates as the central orchestrator, spinning up a configurable number of upload workers and an optional reporter worker. It maintains an internal work queue and runs a continuous loop that switches between polling Kafka for new messages, adding work to its internal queue, sending work to upload workers, and rotating between user-requested profiles.
When the internal queue has work available, it attempts to send work items to upload workers via a shared work channel, keeping any entry that couldn’t be sent for the next iteration. It doesn’t poll for records until its internal queue is empty, which acts as a form of backpressure. For now, it waits until the entire queue is empty, but this logic can be tweaked further.
The upload workers run concurrently, each pulling work from the shared channel and uploading messages to S3 with built-in retry logic. If the user requested reports to be uploaded, results from these upload workers are sent back via a result channel to the reporter worker, which buffers results per topic in memory and periodically uploads consolidated reports when the buffers reach configured limits.
I decided to rely on Kafka’s auto commit mechanism for committing record offsets. Since the only destination supported right now is S3 (which is highly available), manually committing record offsets seemed like overkill. I might revisit this in the future. Since offsets are auto-committed by the Kafka client library, this puts much stronger emphasis on the data loss requirement. This is achieved through retries wherever possible (as described before) and a robust graceful shutdown mechanism.
Graceful shutdown
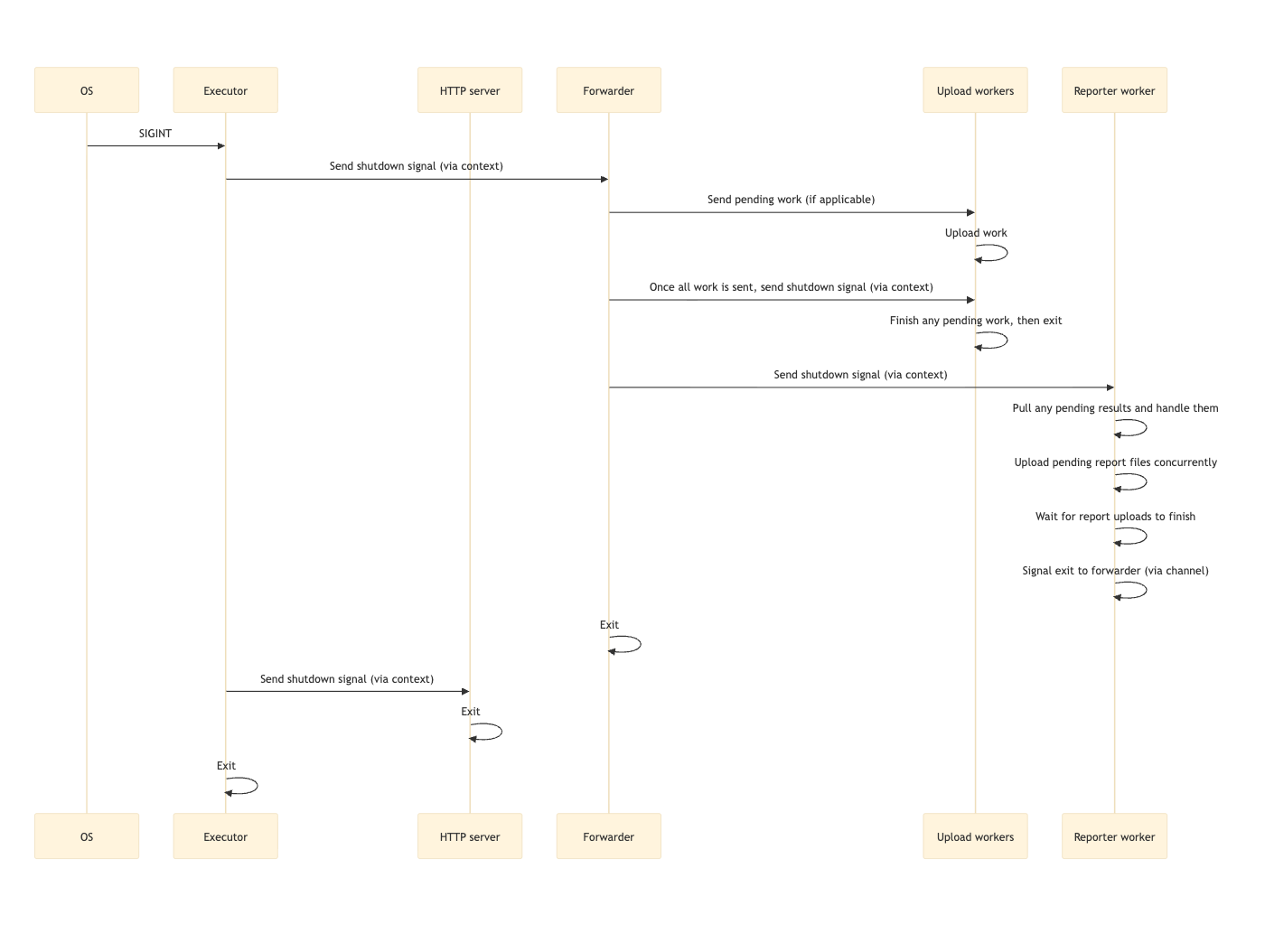
When the application receives a termination signal, the executor immediately propagates a shutdown signal to the forwarder via Go’s context mechanism. The forwarder then performs a controlled shutdown sequence: it first sends any remaining work to the upload workers, then signals them to shut down. Upload workers react to this signal, and start pulling in any pending work. Once every upload worker has shut down, the forwarder signals the reporter worker to begin its shutdown process.
The reporter pulls in any pending results, uploads all buffered report files concurrently, waits for these uploads to complete, and then signals back to the forwarder that it’s safe to exit.
After confirming all workers have exited, the forwarder shuts down. The executor, notified via a channel, then signals the HTTP server (if running) to stop and waits for it to finish before shutting down itself. This cascade ensures that all in-flight work is completed and no messages or reports are lost during shutdown.
As a safeguard, the executor enforces a timeout for graceful shutdown. If components don’t shut down within that time, the executor exits forcefully. Also, if a second shutdown signal is received while components are shutting down, the executor exits immediately.
I heavily relied on Go’s concurrency features while designing this architecture. Go gives you very powerful low-level primitives for building concurrent apps, but it’s also easy to shoot yourself in the foot with them. I’m still forming opinions on whether building concurrent apps at this level of abstraction is a good thing or not. But overall, I’m quite happy with the level of flexibility Go’s primitives gave me in implementing this solution.
It was nice to be able to rely on an existing tool to solve a problem in my new team. I got the forwarder up and running in a day because of the existing foundations of the tool. I definitely could’ve implemented the forwarding mechanism just for my use case (by forking kplay for my team), but building a generic solution that optionally enables features was a lot more fun.